1cat大模型速度测试 - Qwen3.6-35B-A3B-AWQ
测试日期: 2026-05-01 模型: Qwen3.6-35B-A3B-AWQ 接口: OpenAI 兼容接口 并发数: 2
测试结果
| 提示词长度 (tokens) | TTFT (ms) | ITL平均 (ms) | 预填充速度 (tokens/s) | 输出速度 (tokens/s) | 状态 |
|---|---|---|---|---|---|
| 512 | 763.86 | 82.29 | 959.92 | 23.88 | ✅ |
| 1024 | 737.32 | 80.94 | 2452.46 | 24.52 | ✅ |
| 2048 | 1660.03 | 77.98 | 1794.48 | 24.92 | ✅ |
| 4096 | 2428.39 | 75.48 | 2578.02 | 25.74 | ✅ |
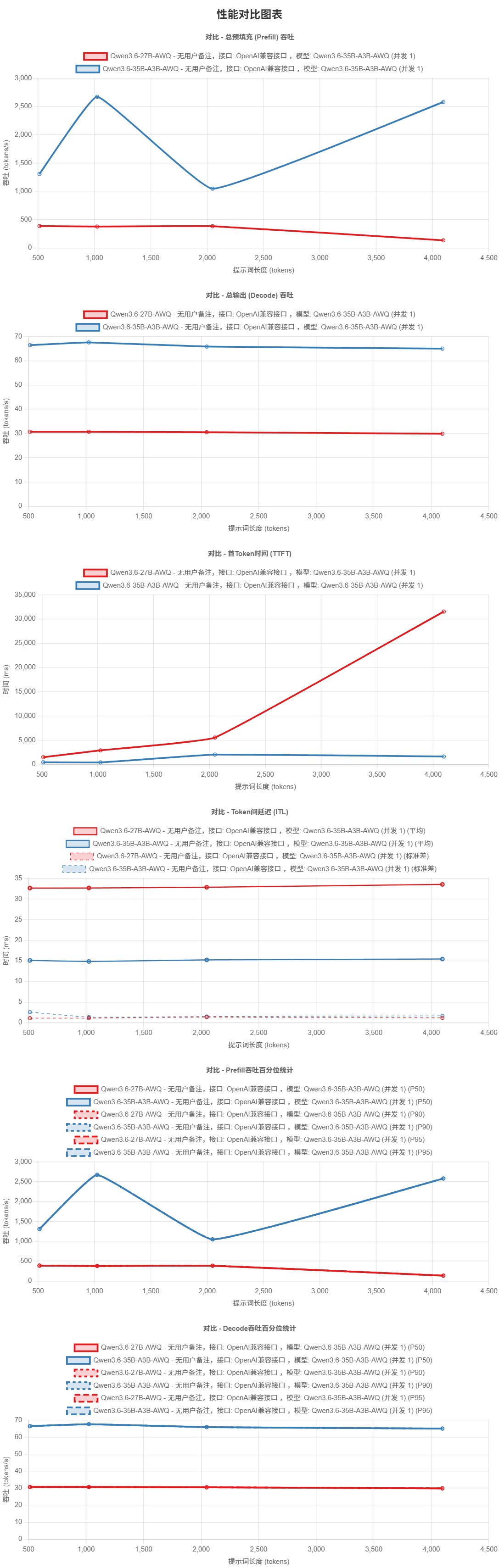
与Qwen3.6-**27b-AWQ对比
**
关键指标说明
- TTFT (Time To First Token): 首 token 延迟,越小越好,用户体验直接影响
- ITL (Inter-Token Latency): 后续每个 token 的间隔时间,越小越快
- 预填充速度: 处理提示词的速度,tokens/s 越高越快
- 输出速度: 生成 token 的速度,tokens/s 越高越快
趋势分析
TTFT (首 token 延迟)
- 512 tokens → 764ms
- 1024 tokens → 737ms(反常低,可能波动)
- 2048 tokens → 1660ms
- 4096 tokens → 2428ms
规律: 随提示词长度线性增长,大致每增加 1024 tokens,TTFT 增加约 900ms。
输出速度
- 稳定在 23-26 tokens/s 之间,几乎不受提示词长度影响
- 这是模型生成阶段的瓶颈,属于固定性能表现
ITL (token 间延迟)
- 稳定在 75-82ms,表现一致
- 与输出速度基本对应(1000ms / 24 tokens/s ≈ 42ms,ITL 偏高说明有额外开销)
预填充速度
- 波动较大:960 ~ 2578 tokens/s
- 提示词越长,预填充效率越高(缓存命中?)
- 512 tokens 时效率最低,可能因为启动开销占比大
测试结果 - 并发 1
并发数: 1
| 提示词长度 (tokens) | TTFT (ms) | ITL平均 (ms) | 预填充速度 (tokens/s) | 输出速度 (tokens/s) | 状态 |
|---|---|---|---|---|---|
| 512 | 371.15 | 14.97 | 1549.88 | 66.95 | ✅ |
| 1024 | 419.09 | 15.14 | 2595.02 | 66.20 | ✅ |
| 2048 | 829.72 | 15.47 | 2550.75 | 64.78 | ✅ |
| 4096 | 1622.44 | 15.83 | 2583.94 | 63.33 | ✅ |
并发 1 vs 并发 2 对比
| 指标 | 并发 1 | 并发 2 | 变化 |
|---|---|---|---|
| 输出速度 | ~65 tokens/s | ~25 tokens/s | 下降 62% |
| TTFT (4096) | 1622ms | 2428ms | +50% |
| ITL | 15ms | 77ms | 415% 暴增 |
| 预填充速度 | ~2580 tokens/s | ~2000 tokens/s | 下降约 22% |
关键发现
- 并发 1 时输出速度是并发 2 的 2.6 倍,单用户体验远优于多用户
- ITL 从 15ms 暴增到 77ms,并发 2 时 token 间明显卡顿感
- TTFT 在并发 1 时增长规律更平滑:512→1024 仅增加 48ms
- 预填充速度在并发 1 时更稳定(波动小)
测试结果 - 并发 4
并发数: 4
| 提示词长度 (tokens) | TTFT (ms) | ITL平均 (ms) | 预填充速度 (tokens/s) | 输出速度 (tokens/s) | 状态 |
|---|---|---|---|---|---|
| 512 | 434.00 | 82.22 | 2198.10 | 24.09 | ✅ |
| 1024 | 637.31 | 85.80 | 3164.40 | 23.28 | ✅ |
| 2048 | 15997.84 | 80.06 | 242.63 | 24.17 | ✅ |
| 4096 | 20493.86 | 77.06 | 389.49 | 24.61 | ✅ |
⚠️ 并发 4 的拐点
短提示词(512-1024)表现尚可,但长上下文出现严重性能衰减:
- 2048 tokens 时 TTFT 暴增到 16 秒
- 4096 tokens 时 TTFT 暴增到 20.5 秒
- 预填充速度暴跌:从并发 1 的 ~2580 降到 242-390 tokens/s
三并发对比总结
| 并发数 | 输出速度 (tokens/s) | ITL (ms) | TTFT 512 | TTFT 4096 | 预填充 512 | 预填充 4096 |
|---|---|---|---|---|---|---|
| 1 | 65 | 15 | 371ms | 1622ms | 1550 | 2584 |
| 2 | 25 | 77 | 764ms | 2428ms | 960 | 2578 |
| 4 | 24 | 79 | 434ms | 20494ms | 2198 | 390 |
关键发现
- 输出速度在并发 2 和 4 时几乎一样 (~24-25 tokens/s)
- 说明 vLLM 的并行能力上限就在 2-4 请求之间
- 再增加并发不会提升吞吐,只会增加延迟
- TTFT 在并发 4 长上下文时出现断崖
- 2048 tokens: TTFT 从并发 2 的 1.7s 跳到 16s
- 4096 tokens: TTFT 从并发 2 的 2.4s 跳到 20.5s
- 并发 4 不适合长上下文场景
- 预填充速度在并发 4 长提示词时暴跌
- 512 tokens 预填充反而比并发 2 快(2198 vs 960),因为短请求竞争少
- 4096 tokens 预填充只有 390 tokens/s,显存碎片化严重
- ITL 在并发 2-4 时稳定在 ~77-80ms
- 并发 2 和 4 的 token 间延迟几乎一样
- 说明瓶颈不在并发数本身,而在显存带宽
建议
- 单用户交互:并发 1,输出速度 ~65 t/s,体验最佳
- 多用户服务:并发 2 最合适,吞吐和延迟的平衡点
- 并发 4 仅适合短上下文场景(< 1024 tokens),长上下文会卡死
- 想跑高并发 + 长上下文,需要更大显存(A100 80GB)